Leveraging Skill-to-Skill Supervision for Knowledge Tracing
(주) 튜링에서 작성하여 AAAI2023 AI4ED 학회에서 발표한 논문입니다 (링크). 기존 Knowledge Tracing의 한계를 짚어보고, 이를 해결하는 방법을 논문으로 작성하였습니다.
만약 Knowledge Tracing이 무엇인지 모르신다면, Riiid Techblog의 글을 보고 오시길 추천드립니다.
기존의 Knowledge Tracing
Knowledge Tracing이란, 사용자가 어떤 문제를 풀려고 할 때 사용자가 그 동안 어떤 학습 기록을 가졌는지 살펴보고 사용자가 문제를 맞힐 확률을 예측하는 과제입니다.
현재 대부분의 Knowledge tracing은 아래와 같은 입·출력 구조를 가집니다.
- 입력: 사용자가 푼 문제의 리스트, 그 문제를 맞혔는지의 여부, 사용자가 문제를 푼 시각
- 출력: 사용자가 특정 문제를 맞힐 확률
그런데, 되돌아보면 한 가자 의문이 생깁니다. 현대의 딥 러닝 모델은 왜 하필 이 세 가지만을 사용하고 있는걸까요? 사용자의 지식 수준을 추적하는 데 쓰일 수 있는 데이터는 무궁무진하고, 딥 러닝 모델이라면 이러한 데이터를 지식 추적에 활용하는 것도 어렵지 않을텐데 말입니다 1 2 3.
조사해 보니 답은 간단했습니다. 현재 Knowledge tracing의 주요 benchmark로 사용되고 있는 ASSISTMENT2009 데이터셋이 가진 데이터가 빈약하기 때문입니다.
특히, ASSISTMENT2009에는 전문가적인 지식이 많이 부족합니다. 전문가가 짜 놓은 단원 간 관계, 전문가가 설정한 난이도 등의 전문가적인 정보는 Knowledge Tracing에 도움이 안 될 수가 없는 정보들이건만, ASSISTMENT2009에는 이러한 정보들이 하나도 없습니다.
어떤 데이터든 잘 소화해낼 수 있는 딥 러닝 기법이 있고, 또 전문가적 지식이 Knowledge Tracing에 도움이 될 거라는 확신이 있는데도 단지 벤치마크 데이터셋이 이전에 만들어졌다는 이유 하나로 쓸 수 있는 데이터를 못 쓰고 있다는 것은 참 안타까운 일입니다. 그런데 때마침 ASSISTMENT 데이터셋은 수학을 다루고 있고, 제가 근무 중인 (주)튜팅에는 많은 수학 전문가가 계십니다. 그렇다면 이 분들에게 조금만 부탁을 해서 기존의 벤치마크 데이터셋에 새로운 데이터를 보강하면 이런 안타까움을 조금은 해결할 수 있지 않을까요?
튜링에서 낸 논문, _Leveraging Skill-to-Skill Supervision for Knowledge Tracing_은 이런 생각에서 탄생하게 되었습니다. Knowledge Tracing 기법들이 새로운 형태의 데이터를 사용할 수 있도록, 이 논문에서는 다음의 세 가지 연구를 수행하였습니다.
- 기존의 데이터셋인 ASSISTMENT4에 단원 간의 관계(Skill-to-Skill Relation)을 더한 ASSISTMENT-SSR 데이터셋을 만들어 공개하였습니다.
- 단원 간 관계 정보를 잘 활용할 수 있는 모델 구조를 제시하였습니다.
- 단원 간 관계 정보 데이터가 Knowledge Tracing에 어떤 효과를 주는 지 분석해 보았습니다.
ASSISTMENT-SSR Dataset
Knowledge Tracing에 사용될 수 있는 정보는 무궁무진합니다. 그렇기에 그 무궁무진한 정보 중에서 기존 데이터셋에 추가할 정보를 골라내는 것은 중요합니다.
추가할 정보를 골라내는 작업은 의외로 간단했습니다. 여러 해 동안 교육 업계에 종사한 저도, 사내 수학 전문가분들도 ASSISTMENT 데이터셋에 수학 교육에 있어 가장 중요한 정보 중 하나가 빠져있음에 동의했기 때문입니다. 바로 단원 간 연관관계(Skill-to-Skill Relation)였습니다.
단원 간 연관관계는 학생의 성취도에 절대적인 영향력을 끼칩니다. 선행 단원을 학습하지 않은 학생은 그 뒤의 단원을 학습해도 제대로 된 지식을 얻을 수 없고, 반대로 선행 단원을 탄탄히 다져놓은 학생은 다른 학생보다 그 뒤의 단원에서 더 많은 것을 얻어갑니다. 이러한 특성 덕분에, 단원 간 연관관계는 Knowledge Tracing에도 유의미한 기여를 할 것이라 예측하였습니다. 모델이 단원 간 연관관계를 이해하고 연관 단원 학습기록의 유무에 따라 맞힐 확률을 조정할 수 있다면 더 좋은 Knowledge Tracing이 가능할 것이라 생각했기 때문입니다.
이러한 이유로, 저희 팀은 4명의 사내 수학 전문가에게 부탁하여 기존의 ASSISTMENT-2009 데이터셋이 가지고 있는 110개의 단원 레이블에 단원별 관계를 하나하나 표기하여 주기를 요청하였습니다. 그리고 이것들을 한 데 모아 ASSISTMENT-SSR(Skill-to-Skill Relation) 데이터셋을 만들었습니다.
Deep Learning Architecture
자세한 내용은 논문을 참조해 주세요
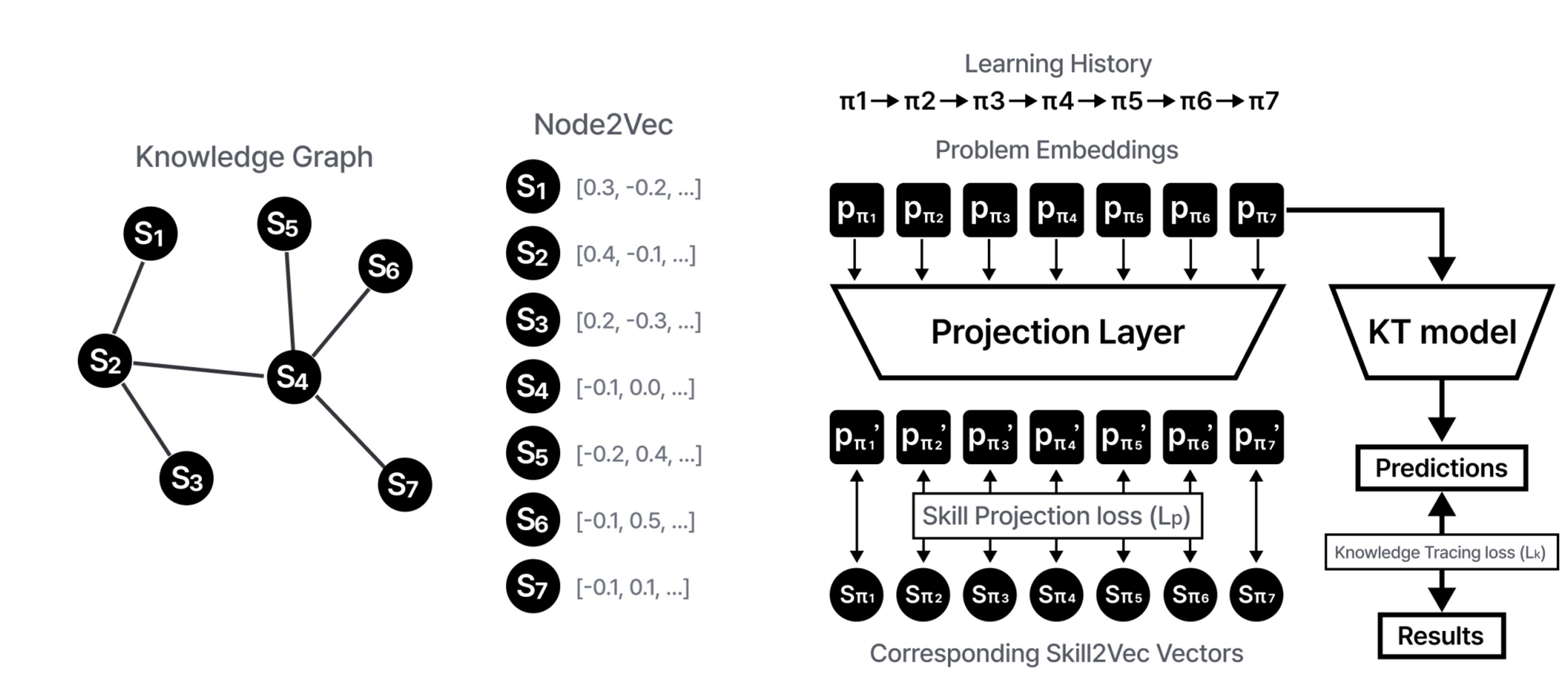
단원 간 관계를 담은 데이터셋을 만들었으니 이제 그것을 활용할 수 있는 방법을 고민해 보았습니다.
위 그림은 단원 간 관계를 활용할 수 있는 딥 러닝 모델 구조의 예시입니다. 모델 구조를 간략하게 설명하면 다음과 같습니다:
- 단원 간 관계를 그래프로 표현합니다. 그래프의 각 node는 단원, edge는 단원 간 관계성의 유무를 나타냅니다
- Node2Vec5을 사용하여 각 node(단원)을 벡터로 표현합니다. 이를 Skill2Vec feature라 합니다.
- 단원 간 관계 외의 기존 ASSISTMENT에 있던 데이터를 사용하여 통상적인 Knowledge Tracing을 수행합니다. 여기에서 나온 loss를 \(L_k\)라 합니다.
- 3.에서 사용한 Embedding을 간단한 Linear layer에 통과시킵니다. 이를 2.에서 만든 Skill2Vec과 비교하여 L2 loss를 구합니다. 이를 \(L_p\)라 합니다.
- \(L = L_k + L_p\)를 loss함수로 하여 학습합니다.
단원 간 관계는 Knowledge Tracing에서 어떤 역할을 하는가?
제안된 모델과 기존 모델을 비교하며 단원 간 관계가 Knowledge Tracing에 어떤 영향을 끼치는지 확인하였습니다.
Knowledge Tracing의 정확도 상승
| Method | AUC |
|---|---|
| Without Projection Loss | 80.81 |
| Random Skill to Skill | 80.90 |
| Expert Guided Skill to SKill | 81.10 |
위 표의 Without Projection Loss는 제안된 방법을 사용하지 않은 Baseline, Random Skill to Skill은 단원간 관계를 랜덤하게 만든 것, 마지막 Expert Guided Skill to Skill은 전문가가 설정한 단원간 관계도를 사용하여 학습한 모델의 성능입니다.
위 표의 Without Projection Loss와 Expert Guided Skill to Skill를 비교해 보면, 전문가의 단원 간 관계도를 사용한 쪽의 AUC가 유의미하게 높습니다. 이는 어떤 방식으로건 단원 간 관계도와 모델 구조가 Knowledge Tracing 성능에 도움이 되었음을 의미합니다.
이러한 성능 향상이 단순히 모델 구조의 변화에서 온 것인지, 아니면 모델이 진짜로 전문가의 의견을 받아들였기 때문에 생긴 것인지 확인하기 위한 Ablation Study도 진행하였습니다. 단순히 단원 간 관계를 랜덤하게 만든 Random Skill-to-Skill과 전문가가 만든Expert Guided Skill to SKill을 비교하여 보면, 전문가의 단원 간 관계도를 사용한 쪽이 더 높습니다. 이는 모델이 전문가의 지식을 실제로 활용하고 있으며 ASSISTMENT-SSR에서 추가된 단원 간 관계도가 실제로 Knowledge Tracing에 유용함을 시사합니다.
단원 간 관계도는 특히 데이터가 적을 때 더 중요하다
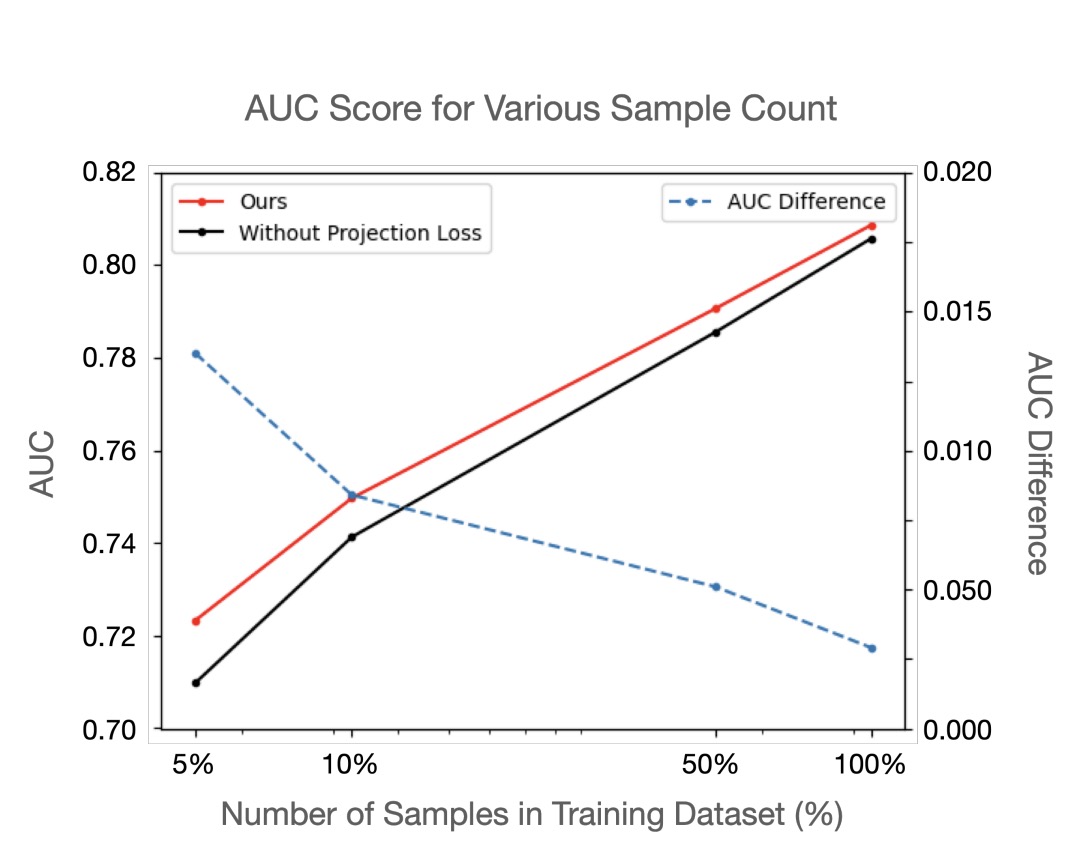
교육 관련 서비스를 운영하다 보면 의외로 데이터가 매우 적은 상황을 많이 마주칩니다. 커리큘럼이 바뀌거나, 새로운 문제가 추가되거나 하는 일이 많기 때문입니다.
일반적으로, AI는 데이터가 쌓여야 일을 잘 할 수 있는 반면 전문가의 지식은 딱히 학생들의 학습 데이터를 필요로 하지 않습니다. 그렇다면, 데이터의 양에 영향을 받지 않는 전문가의 지식은 AI를 학습할 데이터가 적을 때 더 유용하다고 말할 수 있지 않을까요?
이 가설을 검증해보기 위해 ASSISTMENT-2009 데이터셋에서 5%, 10%, 50%의 학생 정보만 사용해 모델을 학습해 보았습니다. 그 결과는 위의 그래프와 같습니다.
위의 그래프에서, 빨간 선은 단원간 관계도를 사용한 모델의 AUC, 검은 선은 사용하지 않은 모델의 AUC를 나타냅니다. 그리고 파란 점선은 그 둘의 AUC 차이를 나타냅니다.
그래프에서 보이다시피, 학습 데이터셋의 크기가 50%, 10%, 5%로 줄수록 단원 간 관계도를 사용한 모델과 사용하지 않은 모델의 성능 차이가 벌어집니다. 데이터 크기에 상관 없는 전문가의 지식이 실제로 데이터가 적을 때 더 좋은 효과를 보이는 것입니다.
요약
- Knowledge Tracing에 사용할 수 있는 정보는 무궁무진합니다. 그런데 지금까지의 AI 모델은 세 가지 데이터만 쓰고 있었습니다.
- 이것은 기존의 데이터셋(ASSISTMENT2009)에서 제공하는 데이터 종류가 부족하기 때문입니다.
- 특히, ASSISTMENT2009에는 단원 간 관계도와 같은 전문가적 지식이 부족해 이러한 지식이 오랫동안 외면받았습니다.
- Knowledge Tracing이 전문가의 지식을 활용하게 하기 위해 기존의 데이터셋인 ASSISTMENT4에 단원 간의 관계(Skill-to-Skill Relation)을 더한 ASSISTMENT-SSR 데이터셋을 만들어 공개하였습니다.
- 단원 간 관계 정보를 잘 활용할 수 있는 모델 구조의 예시를 제공하였습니다.
- ASSISTMENT2009와 ASSISTMENT2009-SSR에 학습된 모델을 비교하여 단원 간 관계 정보가 Knowledge Tracing에 도움이 됨을 밝혔습니다.
- 단원간 관계와 같은 전문가적 정보는 데이터셋의 크기에 무관합니다. 이 때문에 데이터셋의 크기가 작을수록 전문가적 정보가 유용함을 보였습니다.
1: Piech, Chris et al. “Deep Knowledge Tracing.” NIPS, 2015
2: Shin, Dongmin et al. “SAINT+: Integrating Temporal Features for EdNet Correctness Prediction.” LAK21, 2020
3: Ghosh, Aritra and Heffernan, Neil and Lan, Andrew S, “Context-Aware Attentive Knowledge Tracing”, KDD, 2020
4: https://sites.google.com/site/assistmentsdata/
5: Grover, Aditya and Jure Leskovec. “node2vec: Scalable Feature Learning for Networks.” KDD, 2016