Project Description
ICCV 2021 Accepted as Oral Paper!! 자세한 내용을 추후 업데이트 하겠습니다.
NC소프트에서 지원받아 변리사님과 함께 국내 특허를 출원하였습니다. (출원번호 10-2021-0076124)

Natural Language Video Localization (NLVL)은 위의 영상과 같이 비디오와 자연어 쿼리가 주어졌을 때 비디오에서 쿼리가 가리키는 부분을 찾아내는 문제입니다. 앞선 포스트에서는 이 문제를 Fully-supervised learning을 통해 해결하였습니다. 그러나 이러한 접근법은 필연적으로 엄청난 양의 데이터를 모아야 한다는 단점이 있습니다. 특히, NLVL을 위해서는 (비디오, 자연어 쿼리, 쿼리가 가리키는 영역)의 삼중쌍을 모아야 하나, 이러한 형태의 데이터는 annotation cost가 너무 높아 쉽게 만들 수 없습니다.
여기서는 NLVL의 annotation cost 문제를 해결하기 위해 Unsupervised Natural Language Video Localization (uNLVL)문제를 제안하고 이를 해결하는 한 가지 방법을 제시하였습니다. uNLVL은 더 이상 모델 학습을 위해 (비디오, 자연어 쿼리, 쿼리가 가리키는 영역)와 같은 paired data를 필요로 하지 않으며, 오로지 주제와 관련된 비디오 집합, 적당히 큰 자연어 말뭉치, 그리고 미리 학습된 객체 검출기(pre-trained object detector)의 세 가지 unpaired data만으로 NLVL 모델을 학습할 수 있습니다.
결과
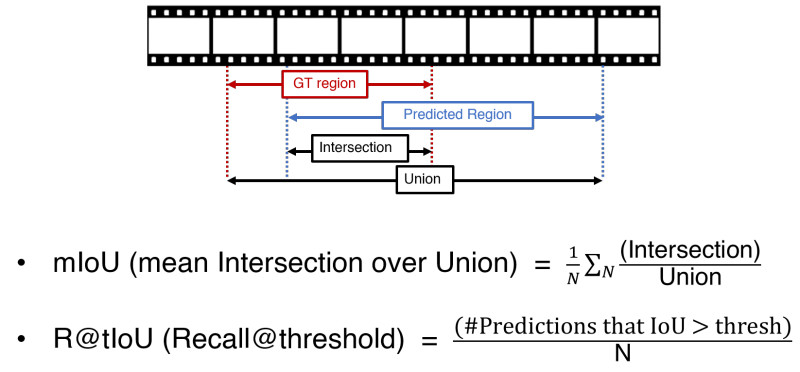
제안된 방법의 성능을 측정하기 위해, 여기서는 R@{0.3, 0.5, 0.7}와 mIoU의 총 네 가지 척도를 사용하였습니다. 위의 그림과 같이, R@{0.3, 0.5, 0.7}는 모델이 예측한 구간과 Ground Truth 구간의 IoU(Intersection over Union)이 각각 {0.3, 0.5, 0.5}를 넘는 예측의 분율을 의미하여, mIoU는 모델 예측과 GT의 mean IoU 입니다.
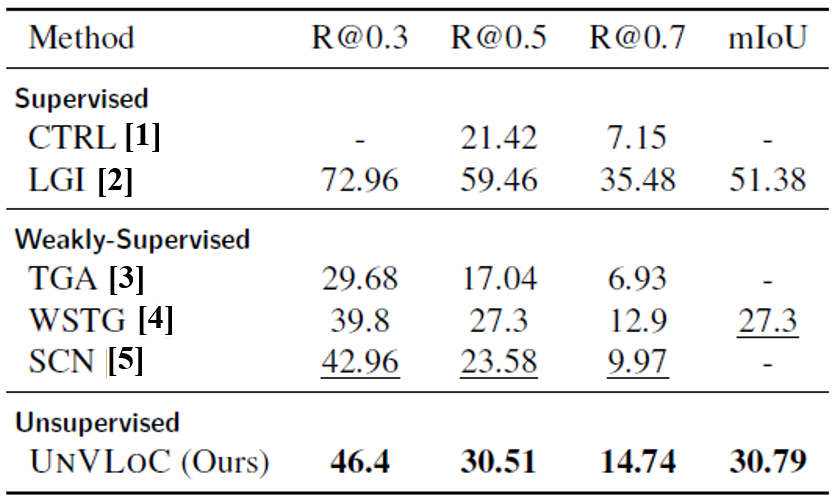
위의 표는 이 프로젝트를 통해 제안된 모델의 성능을 다른 환경(fully-supervised, weakly-supervised)에서 학습된 모델과 비교한 것입니다. 여기에서 제안된 모델(UnVLoC)은 weakly-supervised learning 기반 모델이나 일부 fully-supervised learning 모델보다 크게 높은 성능을 보여주고 있습니다. Unpaired data collection만으로 annotation cost가 큰 paired data를 이용하여 학습된 모델보다 더 높은 NLVL 성능을 얻어낸 것입니다.
후기
- 이번 연구는 아이디어 구상부터 논문 작성까지 한 팀의 리더로서 활동하였습니다.
- 혼자 연구한 경험이야 이전에도 있었지만 팀의 리더로 활동하는 것은 그것과 완전히 다른 경험이었습니다.
- 하루종일 같이 있는 팀원과 시도때도 없이 의견을 교환하고 차이를 조정하는 일이 쉽지많은 않았습니다. 그러나 다행히도 서로 상처 주거나 하는 일 없이 원만하게 일을 끝마칠 수 있었습니다.
- 해야 하는 작업을 팀원에게 분배하는 것도 쉬운 일은 아니었습니다. 그러나 시간이 지나면서 작업을 적절히 배분하게 되었습니다.
- 팀원이 어떤 작업을 좋아하는 지를 잘 파악하여 선호대로 배분하고, 모두가 기피하는 작업은 최대한 돌아가면서 처리했습니다.
- 프로젝트를 논문으로 만드는 과정에서 논문이 써지는 프로세스를 배웠습니다.
- 제가 주도한 연구가 논문이 될 뻔한 적은 이전에도 몇 있었으나, 실제로 인정을 받아 논문 제출까지 제 손으로 끝마친 것은 이 연구가 처음이었습니다.
- 일찌감치 글쓰기를 끝내 놓고 끊임없이 표현을 clear하게 바꾸거나 어조를 defensive하게 바꾸는 작업을 하였습니다. 고된 과정이었고 교수님께 지적도 많이 받았으나 이 과정에서 실용적인 논문 글쓰기를 배울 수 있었습니다.
[1] Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. “Tall: Temporal activity localization via language query”. In ICCV, 2017.
[2] Jonghwan Mun, Minsu Cho, and Bohyung Han. “Local-Global Video-Text Interactions for Temporal Grounding”. In CVPR, 2020.
[3] Niluthpol Chowdhury Mithun, Sujoy Paul, and Amit K Roy-Chowdhury. “Weakly supervised video moment retrieval from text queries”. In CVPR, 2019.
[4] Zhenfang Chen, Lin Ma, Wenhan Luo, Peng Tang, and Kwan-Yee K. Wong. “Look closer to ground better: Weakly supervised temporal grounding of sentence in video”. ArXiv, abs/2001.09308, 2020.
[5] Zhijie Lin, Zhou Zhao, Zhu Zhang, Qi Wang, and Huasheng Liu. “Weakly-supervised video moment retrieval via semantic completion network”. In AAAI, 2020.