현재 실제 한 기업의 서비스와 큰 관련이 있습니다. 많은 디테일이 생략되었습니다.
이 포스트를 읽기 전에, 이전 포스트를 먼저 읽고 와 주세요.
Obfuscation for Large Image
이전 포스트에서, 우리는 성공적으로 이미지를 비식별화 하여 이미지 활용성 과 익명성 의 두 가지의 목표를 모두 달성하는 것을 보았습니다.
그러나, 이전 포스트의 Obfuscator는 실제로 현장에서 사용하기엔 많은 무리가 있습니다. 단순히 개념 실증을 위해 만든 모델이어서, Obfuscator가 크기 128*128 이상의 이미지에서는 잘 작동하지 않기 때문입니다.
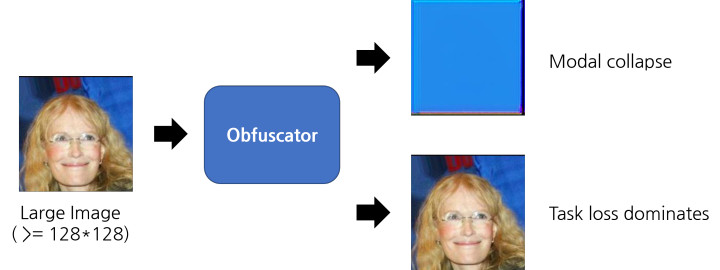
일반적으로, 이전 포스트의 모델을 128*128 이상의 이미지에 적용하면 위의 그림과 같은 결과가 나옵니다: Obfuscator에 Modal Collapse가 일어나 같은 이미지만 만들거나, 학습이 Task loss에 Dominate되어 원본과 똑같은 이미지를 만들거나.
저는 이전의 Obfuscator를 개량하여, 실 사용이 가능한 수준의 모델을 만들기 위한 선행연구를 진행하였습니다.
Idea
커다란 이미지에서 이전의 Obfuscator가 잘 작동하지 못하는 이유는 두 가지입니다.
- GAN 구조의 문제
- 이전 포스트의 Obfuscator는 DCGAN[1]의 파생으로, 학습이 불안정하고 큰 이미지는 다루지 못하는 문제가 있습니다.
- Generation 자체의 어려움
- 이미지가 커지면, 가능한 이미지의 경우의 수가 기하급수적으로 늘어나 Generator 학습에 문제가 되는 것으로 알려져 있습니다.
소개한 두 가지의 문제를 해결하기 위해, 아래와 같은 해결법을 제시하였습니다:
- Obfuscator를 비교적 큰 이미지에서도 잘 동작하는 구조로 바꾸었습니다.
- 최근의 연구 결과에 따르면, Energy-Based GAN의 파생형[2][3]이 커다란 이미지에서도 어느 정도 작동한다고 알려져 있습니다.
- BEGAN[3]을 직접 구현하여 Obfuscator에 적용하였습니다
- 제대로 된 BEGAN 구현체가 없어 직접 구현하여 사용하였습니다.
- Obfuscator가 Original Image가 아닌 Pre-Trained Target Task Netowrk의 Featuremap으로부터 Obfuscated Image를 생성하게 바꾸었습니다.
- 이미지 크기를 N*N, Featuremap 크기를 m*m이라고 했을 때, 기존의 Obfuscator는 N*N -> N*N의 매핑을 학습해야 했지만, 이제는 m*m -> N*N의 비교적 작은 매핑을 학습하게 됩니다.
- Target Task의 Featuremap은 Target Task와 관련된 정보는 가지고 있고, Target Task와 관련 없는 정보는 가지고 있지 않습니다.
- 따라서, Featuremap으로부터 Obfuscated Image를 생성하면 Obfuscator는 더 이상 이미지의 어떤 부분이 Task와 관련 있고 어떤 부분이 관련 없는지 학습하지 않아도 됩니다.
- Neural Network Visualization분야의 연구 결과에 따르면, Target Task Featuremap은 이미지에서 의미를 가지는 기본 단위 (특징적인 점, 곡선 등)에 대한 정보를 많이 담고 있습니다
- 즉, Obfuscator는 더 이상 이미지에서 이러한 기본 단위를 찾을 필요가 없게 됩니다.
Approach
구체적인 방법은 공개할 수 없습니다. 양해 바랍니다.
Qualitative Results
Anonymity

위의 그림은 원본 이미지와 제안된 방법으로 생성된 Obfuscated Image를 비교하고 있습니다. 왼쪽의 두 예시는 Multi-Attribute Classification에 학습된 이미지이고, 오른쪽 두 예시는 Facial Landmark Detection에 학습된 이미지입니다.
- 두 경우 모두, 원본을 알아보기 없을 만큼 Obfuscation이 잘 된 것을 볼 수 있습니다.
- Multi-Attribute Classification에 학습된 obfuscation은 얼굴 형체를 뭉개는 반면, Facial Landmark Detection에 학습된 것은 얼굴 윤곽선을 어느 정도 보존하고 있습니다.
- 이전 포스트에서 설명한 것처럼, Obfuscator 이미지 매핑은 Target task에 필요 없는 정보를 지우기 때문입니다.
Difficulty of De-obfuscation

이전 포스트에서 설명한 것처럼, 몇 장의 이미지를 제외한 대부분의 원본 이미지가 유출된 상황을 가정하고, Obfuscated image -> Original image매핑을 학습하여 보았습니다. 결과는 위의 그림과 같습니다.
그림은 CelebA Dataset의 Facial Landmark Detection Task에 학습된 Obfuscator 모델을 보여줍니다. 위에서부터 차례대로 원본 이미지, Obfuscated Image, 그리고 복원된 이미지입니다.
설령 원본 트레이닝 데이터가 유출되었다 하더라도, Obfuscator의 역방향 매핑을 학습한 모델은 Obfuscated Image를 잘 복원하지 못하는 모습을 볼 수 있습니다. 이전 포스트에서 설명했던 것처럼, Obfuscation 과정에서 Task와 관련 없는 정보가 지워졌기 때문입니다.
Quantitative Results
Target Task Performance & Privacy Protection
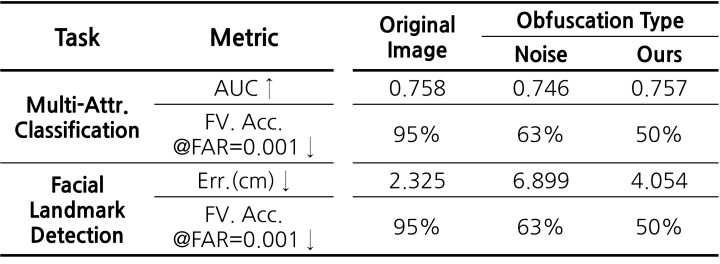
위의 표는 Multi-Attribute Classification과 Facial Landmark Detection 두 가지 Task에 대한 성능입니다. 표에서, Unit 옆의 화살표는 수치가 높을 수록 좋은지, 낮을 수록 좋은지 보여줍니다. 예를 들어, AUC↑는 값이 높을 수록 성능이 뛰어나단 뜻입니다.
먼저, 제안된 모델의 Target Task performance는 Multi-Attribute Classification에서는 원본과 거의 비슷한 성능을 보였고, Facial Landmark Detection에서는 원본보다는 못하지만 다른 obfuscation(Noise)보다는 훨씬 나은 수치를 보였습니다.
한편 Face Varification Accuracy에서는 제안된 모델이 50%에 가까운 성능을 보여 Face varification모델을 성공적으로 속였음을 볼 수 있습니다.
참고:
Face varification accuracy(FV. Acc.)는 같은 사람을 찍은 두 개의 사진이 있을 때 Face varification 모델이 두 사진이 같은 사람을 찍을 것인지 알아맞출 확률입니다.
Obfuscation이 잘 되었을 경우, Face varification 모델은 랜덤한 값을 내게 되어 Fv. Acc. = 50%에 가까워지게 됩니다.
후기
- 비록 선행연구이기는 했지만, 논문 연구에서 출발해 실제로 산업에서 쓰일 만한 모델을 만드는 경험을 했다.
- 논문을 쓰는 연구와 산업에 쓰이는 연구는 다르다. 이러한 점을 많이 체감했다.
- 많은 오픈소스를 빠르게 적용하고 성능을 시험하는 능력이 많이 늘었다.
- 특히 모델에 사용할 GAN 아키텍쳐를 정하는 과정에서 많은 오픈소스를 검토했다.
- 실제로 쓰일 모델은 연산 자원이나 메모리 자원도 충분히 고려해서 만들어야 한다. 이러한 부분을 신경쓰며 연구하는 경험을 했다.
References
[1] “Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks”, In ICLR, 2016
[2] “Energy-based Generative Adversarial Network”, In ICLR, 2017
[3] “BEGAN: Boundary Equilibrium Generative Adversarial Networks”, 2017