현재 실제로 기업에서 사용 중인 프로젝트입니다. 많은 디테일이 생략되었습니다
Image Obfuscation
Objective
Image obfuscation은 이미지 데이터셋을 처리하여 이미지가 다음의 두 가지 성질을 만족하도록 하는 것입니다.
- 익명성: 이미지 내부의 개인정보(얼굴 등)은 사람이 알아볼 수 없는 형태로 가공되어야 하며, 제 3자가 원본을 복원할 수도 없어야 합니다.
- 데이터 활용도: 어떤 특정 Task에 대하여 (e.g. Facial landmark detection, gaze estimation), 익명화된 이미지로 해당 task를 다루는 기계학습 모델을 학습시키더라도 원본 이미지로 학습한 것과 비슷한 성능을 내어야 합니다.
Previous Works
기존의 Image obfuscation 방식에는 다음과 같은 것들이 있습니다:
- 프라이버시와 관련된 부분 (예, 얼굴, 주소)을 찾아낸 뒤 해당 부분을 지우거나[1] GAN을 활용하여 변조하는 방식[2]
- 프라이버시를 탐지하는 모델을 학습하기 위해 많은 데이터를 필요로 합니다
- 프라이버시와 관련된 부분을 제대로 탐지하지 못할 위험이 있습니다. (익명성 보장의 문제)
- 지우거나 변조된 부분에 관한 Task는 학습할 수 없습니다. 예를 들어, 얼굴을 지울 경우 Facial Landmark detection은 학습하지 못합니다. (데이터 활용성의 문제)
- 이미지로 어떤 Task를 학습하더라도 좋은 결과를 기대할 수 없습니다 (데이터 활용성의 문제)
- 아예 이미지를 초저해상도로 만든 뒤 초저해상도에서도 작동하는 모델을 학습하는 방식[3]
- 초저해상도 이미지를 사용하므로 학습된 모델의 성능을 기대할 수 없습니다 (데이터 활용성의 문제)
- 데이터 활용성을 위해 해상도를 높이면 익명화가 제대로 되지 않을 수 있습니다 (익명성 보장의 문제)
위에서 설명한 것처럼, 기존의 방법은 이미지의 활용도를 떨어뜨릴 뿐더러, 개인정보 탐지 과정에서 개인정보를 놓칠 경우 익명성이 보장되지 않을 수도 있다는 치명적인 문제가 있습니다.
Approach
Idea
- GAN기반의 Generative model을 사용하여 obfuscated image를 생성
- 이미지 전체를 익명화할 수 있으므로 익명성이 제대로 보장된다
- 이미지 전체를 익명화하면서도 데이터 활용성을 보장하려면, Image generation과정에 직접 supervision을 줄 수 있는 GAN이 적절하다
- Target Task에 대한 데이터 활용성을 보장하기 위해 Original Image에 Pre-train된 target task network를 사용
- Pre-trained target task network로부터의 피드백을 통해 이미지에서 task와 관련된 부분은 남기고 task와 관련 없는 부분은 지워질 수 있도록 한다.
- 위와 같은 방식으로, Obfuscator는 Target task performance를 보존하면서도 익명화는 제대로 하는 Image mapping function을 학습하게 된다.
Overall Usage Scenario
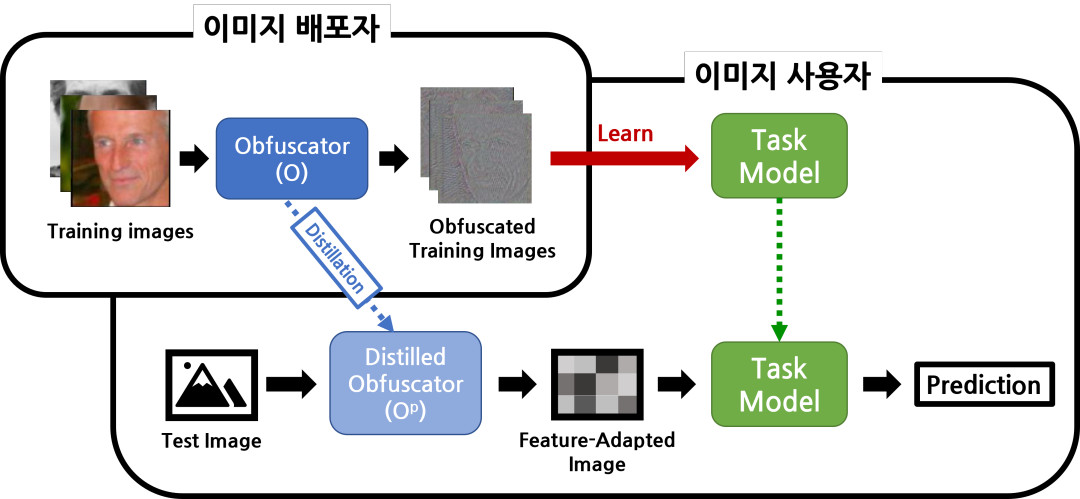
위의 그림은 우리 Image Obfuscation이 어떤 방식으로 이용될 수 있는 지 보여줍니다.
Image obfuscation에 관련된 사람은 프라이버시 걱정 없이 이미지를 배포하려는 사람(이미지 배포자), 배포된 이미지로 모델을 학습하려는 사람(이미지 사용자)의 두 가지 분류로 나눌 수 있습니다.
위의 그림에서, 이미지 배포자는 아래와 같은 일을 합니다:
- Obfuscator를 통해 이미지를 비식별화
- 비식별화된 이미지를 배포
- Obfuscator에 Distillation된 모델(Distillated Obfuscator)을 배포
이미지를 이용하려는 이미지 사용자는, 배포된 자료를 가지고 다음과 같은 일을 합니다:
- 비식별화된 이미지를 사용해 Target Task 모델을 학습
- 학습된 모델을 이용해 Inference할 때는, Distillated Obfuscator를 이용해 인풋 이미지를 Obfuscated Image와 비슷하게 만들어서 Inference 수행
Obfuscator 학습
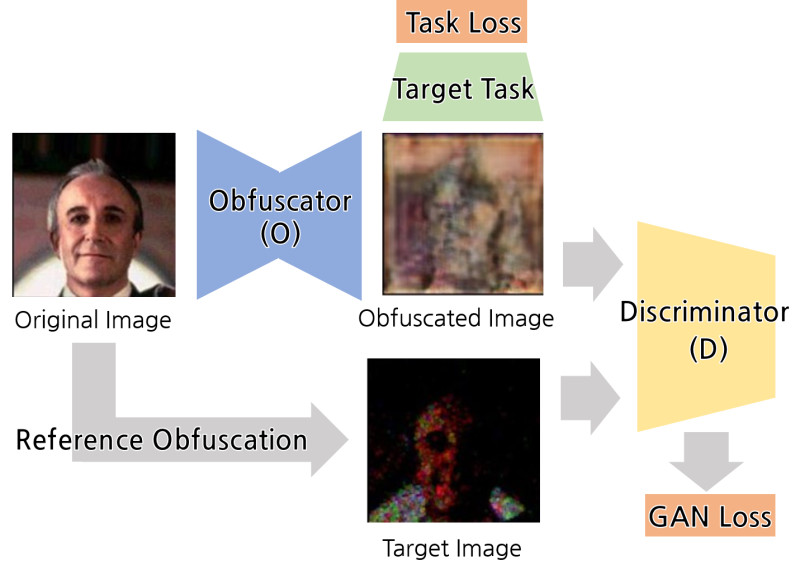
Obfuscator 모델(O)을 학습하기 위해 Adversarial Training 및 Multi-task learning기법을 사용하였습니다.
- 먼저 이미지를 익명화하기 위해 Reference Obfuscation(Noise, Jittering 등의 합성)된 이미지를 만들고, 이것을 Generation Target으로 하여 obfuscated image를만드는 Adversarial Training을 합니다.
- 이 과정에서 Obfuscator(O)는 주어진 이미지로부터 reference obfuscation과 최대한 비슷하게 생긴 이미지를 만드는 방법을 학습하게 됩니다.
- 위에서 나오는 Obfuscated Image(Generator output)를 Pre-train된 Target task network(F)에 input으로 넣어 prediction이 제대로 되는지 확인합니다.
- 이 과정에서 Obfuscator(O)는 인풋 이미지에서 Target Task에 필요한 정보는 남기고 필요없는 정보는 지워서 이미지를 사람이 인식하지 못하는 형태로 바꾸는 법을 학습합니다.
Obfuscated Image 이용
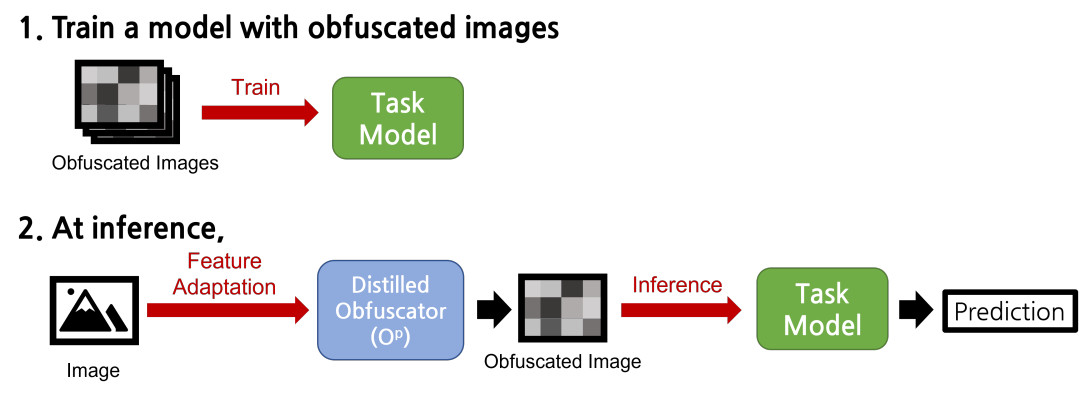
Obfuscated Image를 배포할 때, 사용자에는 다음의 두 가지 자료가 주어집니다:
- Obfuscated Image
- 원본 이미지는 주어지지 않습니다
- 비식별화된 이미지만이 주어지므로 프라이버시를 효과적으로 보호할 수 있습니다
- Diltillated Obfuscator
- 학습된 Task model로 Inference할 때 필요합니다
- Obfuscator의 Inverse mapping을 학습하는 것을 막기 위해 원본 Obfuscator는 주어지지 않습니다
위의 두 자료를 가지고, 사용자는 다음과 같이 Obfuscated Image를 이용할 수 있습니다:
- 비식별화된 이미지를 사용해 Target Task 모델을 학습
- 학습된 모델을 이용해 Inference할 때는, Distillated Obfuscator를 이용해 인풋 이미지를 Obfuscated Image와 비슷하게 만들어서 Inference 수행
- 사용자가 학습된 모델을 배포하고 싶다면, 단순히 Diltillated Obfuscator와 학습된 Target Task Model을 이어붙여 배포하면 됩니다
How it Works?
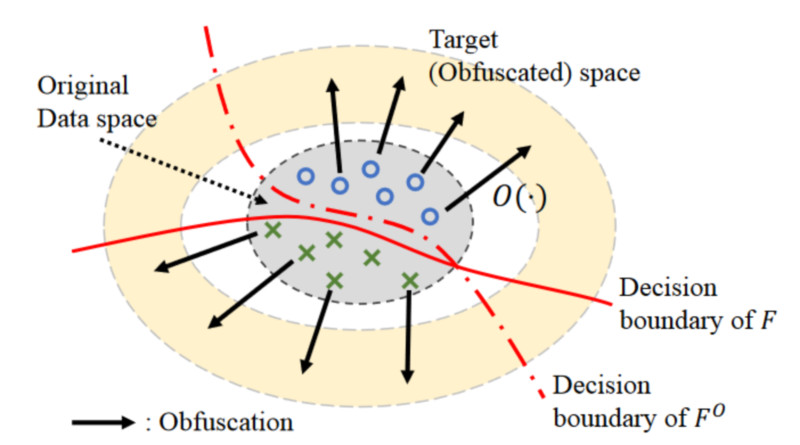
위 그림은 Obfuscator 모델이 어떻게 동작하는 지 설명하는 그림입니다. 그림에서 O 는 Obfuscator 매핑, F는 원본 이미지에 학습된 Target Task 모델의 Decision Boundary, F0는 Obfuscated Image에 학습된 Target Task 모델의 Decision Boundary입니다.
그림에서 Obfuscator(O)는 회색 영역의 원본 이미지를 노란색 영역으로 매핑하는 역할을 합니다. 그런데 이 Obfuscator는 Target Task의 Decision Boundary를 최대한 유지하도록 학습되었기 때문에 이미지의 형태는 다르게 하면서도(O 매핑) 원본 이미지에 대한 Target Task 모델의 Decision Boundary는 비슷하게 (회색 영역에서 F와 F0 비교) 유지할 수 있습니다.
Qualitative Results
아래는 다양한 Task에 대한 Obfuscation 결과입니다. 총 3가지 Task (Multi-Attribute Classification, Facial Landmark Detection, Gaze Estimation)에 대해 실험했습니다.
Multi-Attribute Classification

Obfuscated Image에서,
- 아래의 둘과 다르게 색에 관한 정보가 어느 정도 남아있습니다.
- Multi-Attribute Classification이 “금발”, “흑인”, “립스틱” 등 색에 관한 질문을 하기 때문입니다
- 아래의 둘과 달리, 머리카락이 잘 보입니다
- Multi-Attribute Classification이 “긴 머리”, “대머리”, “곱슬머리” 등의 질문을 하기 때문입니다
Facial Landmark Detection

Obfuscated Image에서,
- 원본 이미지의 대부분이 노이즈로 대체되었으며, 얼굴의 윤곽만을 간신히 알아볼 수 있습니다.
- Facial Landmark Detection에는 얼굴의 특징점 몇 가지를 찾이 위한 정보를 빼면 아무것도 필요하지 않기 때문입니다
Gaze Estimation

Obfuscated Image에서,
- 얼굴 하관이 지워져 있습니다
- 눈 쪽은 잘 보이지만, 입과 그 아랫쪽은 잘 보이지 않습니다
- 얼굴 하관은 시선의 위치와 큰 관련이 없기 때문입니다
해석
- Obfuscated Image는 원본 이미지와 크게 다릅니다
- 프라이버시를 효과적으로 보호할 수 있습니다
- Target Task의 특성에 따라 Obfuscation이 달라지는 것을 볼 수 있습니다
- 이를 볼 때, 우리의 Obfuscator는 실제로 Target Task에 필요한 정보는 남기고 다른 정보는 지우는 식으로 동작함을 알 수 있습니다
Difficulty of De-obfuscation

어떤 악의적인 사용자는 Obfuscated Image를 다시 원본으로 복원하려 시도할 수도 있습니다. 우리 Obfuscation이 이러한 복원 시도에 얼마나 강한지 알아보기 위해, 다음과 같이 최악의 상황을 가정하였습니다.
- 악의적인 사용자가 약 20개의 이미지를 제외한 대부분의 Original Image를 가지고 있다
- 악의적인 사용자는 Obfuscated Image -> Original Image의 mapping을 학습하여 배포된 Obfuscated Image를 복원하려 시도한다
위의 이미지는 이러한 상황에서 복원 시도가 어떻게 되었는지 보여줍니다. 악의적인 사용자가 대부분의 original image - obfuscated image의 쌍을 가지고 있더라도, 악의적인 사용자는 원본 이미지를 복원할 수 없습니다. 이는 아래의 두 가지 이유 때문입니다:
- 사용자는 원본 Obfuscator가 아닌 Distilled Obfuscater만을 가지고 있기 때문에 원본 Obfuscator의 매핑을 학습할 수 없습니다
- Obfuscator가 Target Task와 관련없는 정보를 지웠기 때문에 원본 이미지를 재건하는 데 필요한 정보가 부족합니다.
Quantitative Results
Target Task Performance
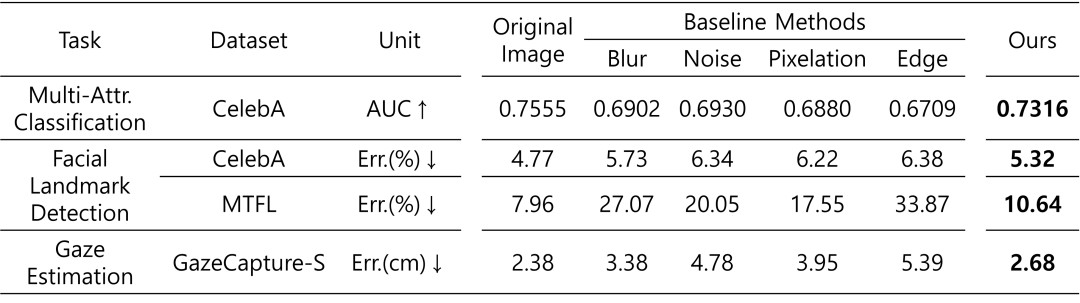
위의 표는 여러 종류의 Obfuscated Image로 학습했을 때의 Target task performance를 보여줍니다. 표에서, Unit 옆의 화살표는 수치가 높을 수록 좋은지, 낮을 수록 좋은지 보여줍니다. 예를 들어, AUC↑는 값이 높을 수록 성능이 뛰어나단 뜻입니다.
모든 Task와 모든 Dataset에서, 우리 Obfuscator는 Baseline obfuscation(Blur, Noise 등)에 비해 크게 높은 성능을 보였습니다. 또한, Origianl Image로 학습한 모델과도 크게 차이 없는 성능을 보였습니다.
이로 미루어 볼 때, 우리 모델은 이미지의 활용성을 제대로 보존하고 있습니다.
Privacy Protection
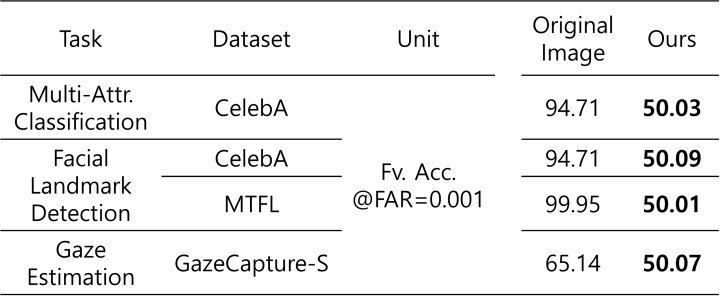
위의 표는 여러 종류의 Obfuscated Image에 Face varification을 수행하였을 때의 결과입니다.
Metric 인 Face varification accuracy(FV. Acc.)는 같은 사람을 찍은 두 개의 사진이 있을 때 Face varification 모델이 두 사진이 같은 사람을 찍을 것인지 알아맞출 확률입니다. Obfuscation이 잘 되었을 경우, Face varification 모델은 랜덤한 값을 내게 되어 Fv. Acc. = 50%에 가까워지게 됩니다.
모든 경우에서, 우리 Obfuscator는 Face varification 모델을 완전히 속여 50%에 극도로 가까운 FV. Acc.를 내게 만들었습니다.
위의 결과로 볼 때, 우리 모델은 프라이버시를 제대로 지킬 수 있습니다.
후기
- 프로젝트가 한창 진행되던 중간에 끼어들어 배울 것이 많았다.
- 처음 팀에 들어왔을 때, 일단 관련 분야의 중요한 논문들을 추천해 달라고 부탁했다. 그것들을 공부해 배경 지식을 쌓았다
- 이미 짜여져 있는 코드를 이해하기 위해 디버거를 활용하여 코드가 돌아가는 과정을 쭉 훓어보았다.
- 훑어보는 과정에서, 특히 프로젝트 코드의 디자인 패턴을 이해하고 이를 체득하려 노력했다.
- 이 과정 덕분에 이후 실제 코딩을 할 때 큰 마찰이 없었다.
- 모르는 것이 있을 때마다 머뭇거리지 않고 적극적으로 질문했다.
- 다른 사람과 제대로 된 협업을 하는 것은 이 프로젝트가 처음이었다. 이 때문에 업무상의 커뮤니케이션에서 많은 것을 배웠다.
- 특히, 커뮤니케이션에서 가장 중요하지만 쉽게 있는 것들에 대해 많이 신경쓰게 되었다.
- 말로 하는 커뮤니케이션에는 항상 misunderstanding의 위험이 있다는 것을 체감했다.
- 새로운 개념을 설명하기 위해 기존에 없는 합성어를 만들어내지 않고 되도록 풀어서 설명하게 되었다
- 복잡한 개념을 설명할 때는 일단 그림부터 그리고 보게 되었다.
- 말로 무언가를 설명할 때는 항상 중간중간 이해도를 체크하게 되었다
- 주기적인 업데이트의 중요성을 많이 체감했다
- 연휴가 겹치고, 각자 맡은 일도 달라서 열흘 정도 서로 업데이트를 하지 않았던 적이 있다. 업데이트를 하지 않으니 이후 아이디어를 나누는 데 많은 어려움이 있었다.
- 이후로는 어떻게든 시간을 만들어서라도 1주일에 두 번 정도는 팀원과 업데이트를 하려고 노력하고 있다
References
[1] “Face/off: Preventing privacy leakage fromphotos in social networks”, In CCS, 2015
[2] “DeepPrivacy: A Generative Adversarial Network for Face Anonymization”, In ISVC, 201919
[3] “Privacy-Preserving Human Activity Recognition from Extreme Low Resolution”, In AAAI, 2017