Image-in-Image Steganography
대학원에 입학하고 처음으로 수행한 온보딩 프로젝트입니다.
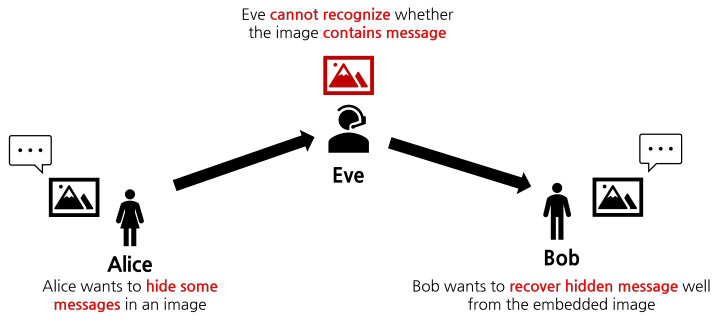
위의 그림과 같이, 이미지 스테가노그래피는 이미지 속에 다른 정보 (텍스트, 이미지 등)를 숨기되 이미지 속에 정보가 숨어 있다는 사실을 다른 사람이 알지 못하게 하는 Task입니다.
일반적인 암호화는 정보를 알아보지 못하게 하는 것을 목표으로 하나, 스테가노그래피는 정보가 숨겨져 있다는 사실 자체를 모르게 한다는 부분에서 암호화와 차이가 있습니다.
현재 스테가노그래피 관련 연구는 이미지 안에 텍스트를 숨기는 기법에 집중되어 있습니다[1]. 이미지 안에 텍스트를 숨길 경우 픽셀당 숨겨지는 정보량(bpp, bits per pixel)은 0.1bit 내외인 반면, 이미지를 숨기면 bpp = 8bits * 3(RGB) = 24bits로 아주 어려운 문제가 되기 때문입니다.
이러한 이유로, 최근 기계학습을 활용해 이미지 스테가노그래피를 하는 연구가 하나 등장했습니다[2]. 이 연구는 기본적인 LSB 인코딩 알고리즘보다는 보여주나, 여전히 (1)숨겨진 이미지가 쉽게 노출되고 (2) 이미지 변형에도 취약한[2] 문제를 가지고 있습니다.
따라서, 이 프로젝트는 이전에 개발된 Image-in-Image Steganography 알고리즘[2]을 개량하여 다음의 두 가지 성질을 만족하게 하는 것을 목표로 하였습니다:
- 숨겨진 이미지가 쉽게 보이지 않아야 한다
- 기존 알고리즘은 수치상(PSNR, SSIM등) 좋은 결과를 보여주었지만, 실제로는 숨긴 이미지가 생각보다 잘 보였습니다.
- 이미지의 경우, 대부분을 잘 숨기더라도 작은 edge 하나를 숨기지 못하면 금방 눈에 띄게 됩니다.
- 이미지가 어느 정도 변형되어도 안에 든 정보에는 문제가 없어야 한다
- 기존 알고리즘은 간단한 warping, jpeg compression등에도 안에 있는 정보가 쉽게 망가졌습니다.
Previous Work: Hiding Images in Plain Sight
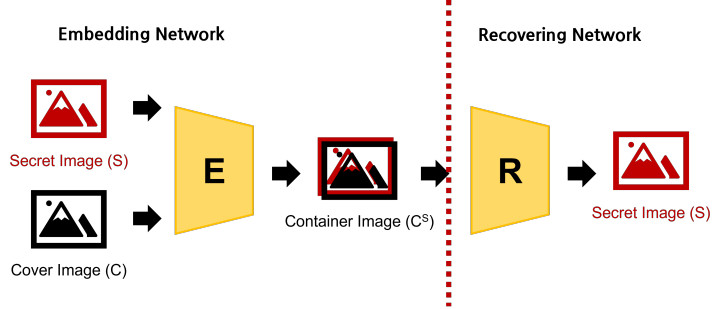
위의 그림에서, Cover Image는 겉으로 보이는 이미지, Secret Image는 숨겨질 이미지, Container Image는 Secret Image에 대한 정보를 가지고 있지만 겉보기에는 Cover 처럼 보이는 이미지, Recovered Image는 Container Image로부터 다시 끝
모델은 Secret Image와 Cover Image로부터 Container Image를 만들어내는 Embedding network와 Container Image에서 Recovered Image를 생성하는 Recovering network로 나눠져 있습니다. 학습 시에는 이 둘이 같이 학습되며, 학습이 완료되면 메시지를 보내는 사람과 받는 사람이 각각 Embedding network와 Recovering network를 나눠 가집니다.

위 그림은 기존 알고리즘으로 Image-in-Image Steganography를 했을 때의 예시 두 가지입니다. 예시에서 Container Image를 자세히 보면, 위쪽 예시의 경우 하늘에서 사람의 윤곽이 보이고, 아래쪽 예시에서는 문고리 부분의 윤곽이 드러나는 것을 볼 수 있습니다.
또, 그림에는 없지만, 만약 container Image를 약하게라도 변형할 경우, Recovered Image는 아무 의미 없는 Noise 형태로 변하게 됩니다.
Approach
Transformation Layer
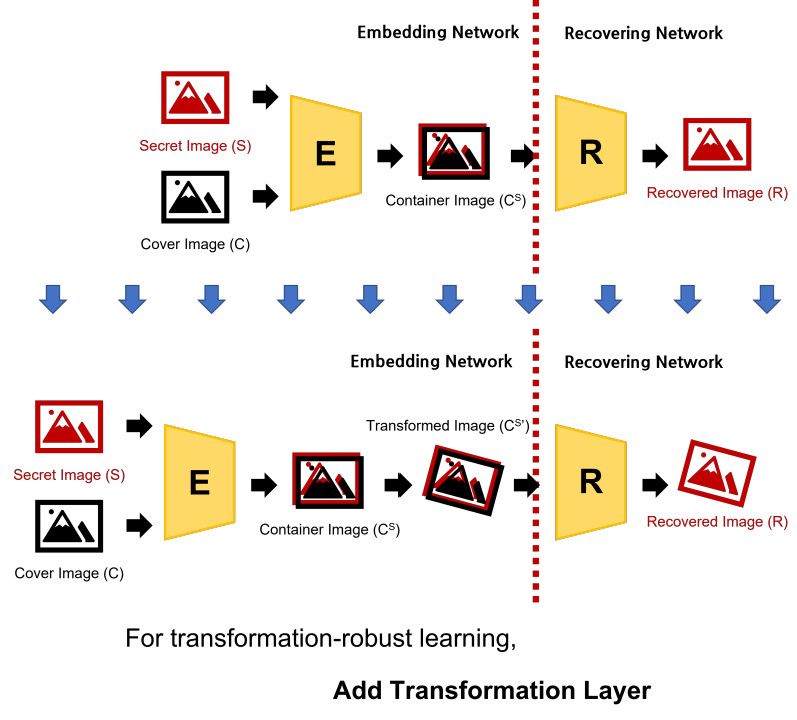
기존의 Taxt-in-Image 알고리즘[1]에서는, 뉴럴 네트워크 학습 과정에서 각종 이미지 변형(Warping, jpeg compression)을 시뮬레이션하는 Transofmration layer를 추가하는 방식으로 Container Image의 변형에 대응하였습니다.
같은 방식으로, 저도 위의 그림과 같이 기존 모델에 Transformation layer를 추가하였습니다.
Feature Encoding Secret Image
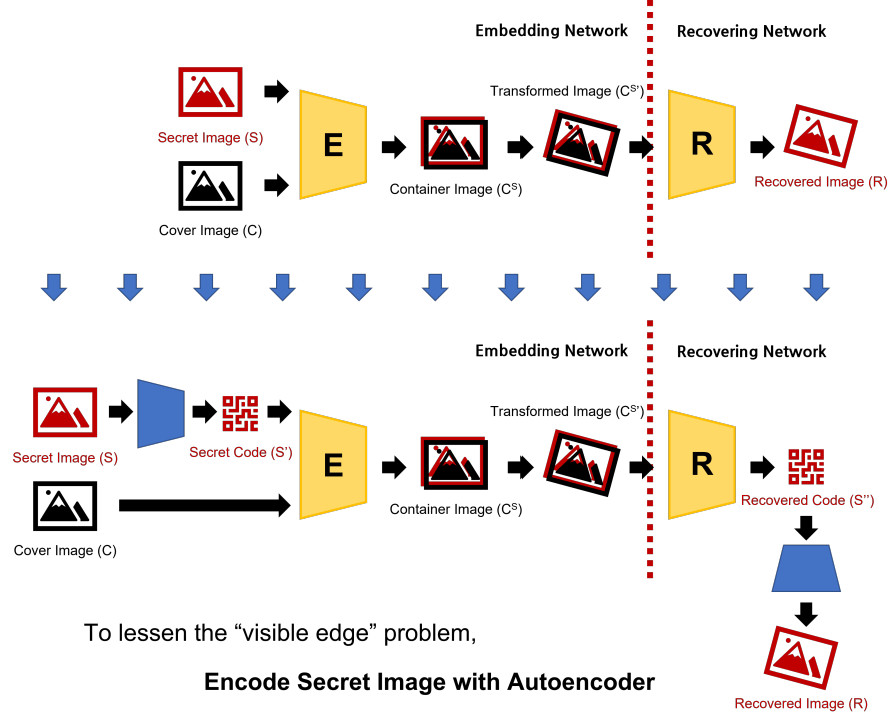
이전 기법[2]은 이미지의 대부분을 숨기더라도 일부의 edge를 놓쳐 결과적으로 숨겨진 이미지가 잘 보이는 문제가 있었습니다. 이러한 문제를 완화하기 위해, 저는 Embedding network와 Recovering network가 secret image 대신 Autoencoder로 인코딩된 secret image의 feature를 쓰도록 하였습니다.
이렇게 하면, Edge에 관한 정보가 Container image에 explicit한 형태로 들어가지 않게 되어 Container image에서 Secret image의 edge가 보이는 현상을 완화할 수 있습니다.
Results

위의 그림은 프로젝트로 만들어진 모델의 결과물입니다. 위에서부터 차례대로 Cover Image(a), Secret Image(b), Container Image(c), Recovered Image(d)입니다.
그림에서 보이다시피 Cover(a)에 Secret(b)를 숨겼음에도 둘을 합성한 Container Image(c)는 Cover(a)와 별다른 차이가 없는 것을 볼 수 있습니다. 마찬가지로 (c)에서 복원된 Recovered Image(d)는 원본 Secret Image(b)와 큰 차이 없는 것을 볼 수 있습니다.
더하여, 모든 이미지는 합성된 이후에 각기 다른 수준의 변형을 거쳤으나(Rotation, jpeg compression 등), 결과물의 질은 변형의 강도와 크게 상관없이 좋습니다. 이것은 이전의 모델[2]에서는 불가능했던 것입니다.
후기
- 연구실 온보딩을 겸해서 처음으로 해 본 연구 프로젝트였다
- 연구 프로젝트가 어떻게 진행되는 지 경험했다
- 실험 내역을 주기적으로 백업하는 습관을 들이는 계기가 되었다.
- 연구가 끝나고 6개월 쯤 지난 뒤에, 이 프로젝트 관련 내용이 필요해 찾으려고 보니 디스크가 망가져 실험 기록이 대부분 날아가 있는 것을 목격한 경험이 있다.
- 이 경험 이후로 실험을 하면 일단 구글 시트에 결과를 적어넣는 습관을 들였다.
- Steganography 관련 논문은 대부분 코드를 공개하지 않아 직접 Reproducing해야 했다
- 이 과정에서 논문을 보고 모델을 구현하는 경험을 많이 했다.
- 이미지 스테가노그래피를 해 보자는 생각은 순전히 나 혼자 떠올린 것이었다. 이 때문에 프로젝트를 시작하기에 앞서 많은 사람들에게 프로젝트를 PR해야 했다.
- 정기 랩 세미나 시간을 열심히 준비하여 기계학습 스테가노그래피 분야에 대한 소개와 내 아이디어에 대한 PR 시간으로 활용하였다. 열심히 준비한 만큼 좋은 반응을 얻어 프로젝트를 시작하는 데 많은 도움이 되었다.
[1] Jiren Zhu, Li Fei-Fei et al. “HiDDeN: Hiding Data with Deep Networks”, ECCV, 2018
[2] Shumeet Baluja, “Hiding Images in Plain Sight: Deep Steganography”, NeurIPS, 2017